

. Вербальные ассоциации и организация лексикона человека // Филологические науки. 1989. № 3. - С. 39-45.
Проблемы ассоциаций, традиционно считавшихся предметом прежде всего психологии, в последнее время все больше привлекают внимание языковедов. Однако лингвистический статус, отношение к системе языка и речи, принципы классификации словесных ассоциаций остаются малоизученными. Настоящая работа посвящена экспериментальному исследованию некоторых аспектов природы и статуса стандартных вербальных ассоциаций в связи с изучением лексикона человека.
Известно, что объективность результатов ассоциативного эксперимента (АЭ) может быть подтверждена или, наоборот, опровергнута путем их сопоставления с результатами, полученными при помощи других методов лингвистического анализа, например, дистрибутивно-статистического[1]. Сопоставления подобного рода проводятся главным образом в целях изучения значений лексических единиц и их совокупностей[2]. Закономерной является также постановка вопроса о том, где и как могут быть обнаружены языковые лексические объединения, соответствующие по своему составу и структуре ассоциативным полям (АП), и могут ли они вообще быть обнаружены способами, отличными от АЭ.
Выявление лексических объединений, одноплановых с АП, вряд ли возможно с ортодоксальной точки зрения на язык только как на систему значимостей, оппозиций и т. п., так как при этом обычно исходят из понятий общих и различительных признаков, интегральных и дифференциальных компонентов значений и т. п., что приводит к конструированию либо линейных рядов синонимов, антонимов, омонимов и т. д., либо различного рода лексико-семантических полей и групп, то есть объединений слов, организованных на основе общих признаков формы или содержания и представляющих собой довольно высокую степень научной абстракции. АП, как известно, имеют несколько иной характер организации. Поэтому их сопоставление с традиционно выделяемыми полями и группами слов наталкивается на ряд принципиальных трудностей и малоэффективно.
С другой стороны, исследователями языка уже достаточно давно подчеркивается мысль о необходимости отойти от «жестких логических схем построения», приводящих к созданию «искусственных моделей, весьма далеких от предполагаемых «естественных» систем языка»[3]. Однако и в этом случае сам предмет изучения, как правило, априори задается исследователем на основе тех же представлений об объединениях слов с общим значением, в результате чего объективным оказывается лишь само предопределенной субъектом группы, но не ее выявление. То есть исследователем языка произвольно выбирается некоторая группа слов с определенным общим элементом значения, которая извлекается из системы и лишь затем уже изучается с той или иной степенью объективности[4]. И хотя такое изучение вполне правомерно и необходимо, оно в ряде случаев оказывается недостаточным.
В то же время наряду с исследованиями лексико-семантических и тематических объединений слов, выделяемых на основе их сходства, наличия общих признаков в их форме или содержании, в научной литературе можно отметить ряд работ, в которых рассмотрение лексических объединений проводится с принципиально иных позиций, а именно – с ситуативно-тематических позиций, основывающихся на том, что коммуникативно-номинативная и речемыслительная деятельность людей всегда заданы и организованы тематически, всегда предметны. В этом случае к тематически группам слов относят «такие классы слов, которые объединяются оной и той же типовой ситуацией ил одной темой… но общая идентифицирующая (ядерная) сема для них необязательна»[5]. Эти объединения образуют слова разных частей речи, а сами объединения являются комплексными (или комбинаторными) полями, «возникающими при сложении парадигматических и синтагматических смысловых полей»[6]. считает, что « основной единицей тематического списка является тематико-ситуативная группа… слов, связанных с одной темой»[7] и что частотность конкретного слова – «это локальная частотность, определяемая при помощи статистического анализа определенного тематически однородного массива»[8]. «…Весьма значительные по количеству лексем словарные группы, ряды, микросистемы, построенные на основе сферы общности функционирования и использования их компонентов», которые «называются тематическими, или предметно-отраслевыми», отмечает [9]. Аналогичного рода поля и группы рассматриваются рядом исследователей и в работах, посвященных вопросам преподавания неродных языков: (тематические группы), (тематико-понятийные классы), и (тематические поля) и др.
Одним из возможных способов обнаружения ситуативно-тематических полей (СТП), на наш взгляд, может быть дистрибутивно-статистический анализ слов, задающих тему (слов-тем: Город, зима, лес и т. д.). В результате такого анализа и выявляются, прежде всего, стандартные совокупности лексем языкового характера, объединяющихся именно «одной и той же ситуацией» употребления, определяемой темой. Оптимальными «интервалами текста»[10] в этом случае скорее всего будут интервалы, соответствующие «минимально необходимым и достаточным контекстам»[11], которые находим, главным образом, в виде иллюстративного материала по употреблениям того или иного слова в словарных картотеках.
СТП могут выявляться и в результате анализа лексики целостных связных текстов на одну тему. Совокупности постоянно повторяющихся в этих текстах слов должны образовывать лексические объединения, самой «практикой речи отлагаемые во всех, кто принадлежит к одному общественному коллективу»[12]. Следовательно, с одной стороны, это объединения, существующие в «языковом материале» («совокупности текстов» – ) и являющиеся элементами языковой системы, с другой – это объединения, отражаемые в языковом сознании людей и являющиеся элементами «языковой способности» (), Наиболее стандартные (устойчивые, социально значимые) части СТП можно рассматривать в качестве достаточно стабильных языковых совокупностей и получать путем статистической обработки необходимого массива тематически однородных текстов, что, в сущности, также является одним из вариантов дистрибутивно-статистического анализа слова-темы, осуществляемого на основе использования «максимальных интервалов текста» – целых текстов. Основным и непременным условием выявления таких полей является условие тематического единства этих текстов, их семантической цельности – быть обозначениями все равно какой, но одной и той же ситуации, то есть естественное, реальное условие любого осмысленного речевого общения вообще.
Обнаружение подобных лексических объединений возможно, очевидно, и с некоторых других позиций, например идеографических (на основе закона о «семантическом согласовании»)[13]. Однако в любом случае необходимо признать реальность и языковой характер СТП, а также их значительную близость по своему составу и структуре к соответствующим им (одноименным с ними)[14] АП, которые, в свою очередь, могут быть расценены в качестве тематически однородных лексических объединений, задаваемых и организуемых словом-стимулом (по существу, тоже темой). Есть, по-видимому, все основания считать АП психологическими аналогами соответствующих СТП. Сказанное лишний раз свидетельствует о правомерности сопоставления состава и структуры АП с составом и структурой СТП[15].
Для осуществления такого сопоставления нами был проведен АЭ (слово-стимул береза) с неограниченным числом реакций, но ограниченный по времени ответа тремя минутами (160 испытуемых – студенты и слушатели подготовительных курсов филологических факультетов вузов Ленинграда). С другой стороны, была проведена выборка употреблений слова береза и его одноконцептуальных производных (березка, березонька и т. п.) в «минимально необходимых и достаточных контекстах». Источниками послужили: 1. Материалы Большой картотеки Словарного сектора ЛОИЯ АН СССР. 2. Есенина. 3. Популярные песни на слова советских поэтов (24 песни). 4. Фольклорные произведения (32 русские народные песни). Кроме того, была обследована лексика различных стилей и жанров о березе в пособии «На уроке – анализ текста»[16] с добавлением еще одного текста (Т. Горева. Береза), подготовленная авторами пособия, но не включенного в окончательную редакцию. 2. Лексика экспериментальных текстов о березе, написанных испытуемыми (50 человек – студенты и слушатели подготовительных курсов филологических факультетов вузов Ленинграда)[17].
Анализу была подвергнута только полнозначная лексика. Из сопоставления по ряду причин, связанных с особенностями сбора материала, были исключены слово береза и его производные с тем же концептуальным ядром лексического значения. В целом, по данным АЭ, было проанализировано 1550 словоупотреблений (479 различных лексем), по данным текстовых источников (Т) – 4709 словоупотреблений (2203 различные лексемы). Для проведения сопоставительного анализа были составлены алфавитно-частотные и частотные списки лексики АЭ и Т[18]. За основание сравнения принимались данные Т, на которые накладывались данные АЭ, что позволяло выявлять степень и характер их соответствия лексике Т. В данных АЭ обнаружено 283 лексемы, общие с лексемами Т (![]() 59%). Эти 283 лексемы представляют 1312 словоупотреблений, что составляет
59%). Эти 283 лексемы представляют 1312 словоупотреблений, что составляет ![]() 85% всех словоупотреблений АЭ. Другими словами,
85% всех словоупотреблений АЭ. Другими словами, ![]() 85% полнозначных слов АП, полученного в результате АЭ со словом-стимулом береза, совпадает с данными соответствующего СТП, полученного в результате дистрибутивно-статистического анализа лексики связных текстов о березе различного размера и характера, Весьма существенным является совпадение прежде всего наиболее частотных лексем АП с лексемами СТП. Так, совпадают все 44 лексемы с частотностью от 8 до 76, то есть 100%. Из 50 лексем с частотностью от 7 доупотребления) совпадают 49 лексем (98%), или 866 употреблений (99%). Из 82 лексем с частотностью от 4 доупотреблений) совпадают 80 лексем (98%), или 1013 употреблений (9%). Остальные несовпадающие лексемы находятся в области частотностей менее 4, что составляет, по существу, периферию («хвост») поля.
85% полнозначных слов АП, полученного в результате АЭ со словом-стимулом береза, совпадает с данными соответствующего СТП, полученного в результате дистрибутивно-статистического анализа лексики связных текстов о березе различного размера и характера, Весьма существенным является совпадение прежде всего наиболее частотных лексем АП с лексемами СТП. Так, совпадают все 44 лексемы с частотностью от 8 до 76, то есть 100%. Из 50 лексем с частотностью от 7 доупотребления) совпадают 49 лексем (98%), или 866 употреблений (99%). Из 82 лексем с частотностью от 4 доупотреблений) совпадают 80 лексем (98%), или 1013 употреблений (9%). Остальные несовпадающие лексемы находятся в области частотностей менее 4, что составляет, по существу, периферию («хвост») поля.
КТП «Береза»
(обобщенный частотный список лексем АП и СТП с суммарной частотностью > 14)
№ п/п | Лексема | КТП | АП | СТП | № п/п | Лексема | КТП | АП | СТП | |
1 | Белый | 144 | 76 | 68 | 25 | Нежный | 26 | 20 | 6 | |
2 | Дерево | 96 | 30 | 66 | 26 | Поле | 26 | 11 | 15 | |
3 | Стройный | 82 | 66 | 16 | 27 | Плакучий | 25 | 12 | 13 | |
4 | Русский | 74 | 35 | 39 | 28 | Земля | 24 | 4 | 20 | |
5 | Роща | 74 | 33 | 41 | 29 | Сережки | 24 | 13 | 11 | |
6 | Лес | 72 | 27 | 45 | 30 | Ветка | 23 | 9 | 14 | |
7 | Кудрявый | 57 | 42 | 15 | 31 | Дуб | 23 | 9 | 14 | |
8 | Стоять | 57 | 16 | 41 | 32 | Красота | 21 | 11 | 10 | |
9 | Зеленый | 53 | 36 | 17 | 33 | Красавица | 20 | 12 | 8 | |
10 | Лист | 47 | 20 | 27 | 34 | Трава | 19 | 11 | 8 | |
11 | Сок | 43 | 24 | 19 | 35 | Весна | 19 | 10 | 9 | |
12 | Тонкий | 41 | 24 | 17 | 36 | Песня | 19 | 6 | 13 | |
13 | Россия | 41 | 15 | 26 | 37 | Листва | 19 | 5 | 14 | |
14 | Родина | 36 | 20 | 16 | 38 | Небо | 18 | 14 | 4 | |
15 | Красивый | 36 | 15 | 21 | 39 | Солнце | 18 | 12 | 6 | |
16 | Белоствольный | 34 | 25 | 9 | 40 | Осина | 18 | 7 | 11 | |
17 | Веник | 34 | 21 | 13 | 41 | Светлый | 17 | 6 | 11 | |
18 | Расти | 32 | 12 | 20 | 42 | Дрова | 16 | 9 | 7 | |
19 | Ствол | 32 | 9 | 23 | 43 | Дом | 16 | 5 | 11 | |
20 | Девушка | 31 | 20 | 11 | 44 | Клен | 16 | 4 | 12 | |
21 | Кора | 31 | 9 | 22 | 45 | Река | 16 | 5 | 11 | |
22 | Молодой | 30 | 7 | 23 | 46 | Гриб | 15 | 9 | 6 | |
23 | Береста | 27 | 16 | 11 | 47 | Сосна | 15 | 5 | 10 | |
24 | Высокий | 27 | 16 | 11 | 48 | Плакать | 15 | 4 | 11 |
Весьма показательно также, что коэффициент ранговой корреляции (ρ) всех совпадающих 283 лексем АП с соответствующими лексемами СТП = + 0, 53, а 49 наиболее частотных лексем АП (с частотностями > 6) = + 0,62, то есть они проявляют достаточно высокую положительную корреляцию.
Примечание.
Коэффициент ранговой корреляции вычисляется по формуле:
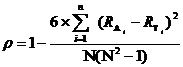 ,
,
где Ai – частотность лексемы Ni в АП; Ti – частотность лексемы Ni в СТП; RAi – ранг лексемы Ni в АП; RTi – ранг лексемы Ni в СТП; N – количество лексем.
Результаты сопоставления еще раз подтверждают реальность СТП (как элементов языковой системы) и их прямых психологических аналогов АП (как элементов языковой способности), дополняющих и обогащающих друг друга при их выявлении[19]. Обобщение данных АП и СТП позволяет с наибольшей полнотой и надежностью выявлять существенные (стандартные, устойчивые) части лексических объединений, тематически организованных в языковом сознании людей в коммуникативных целях, которые скорее всего могут быть охарактеризованы как коммуникативно-тематические поля (КТП).
Рассматриваемые объединения слов, по нашему мнению, играют исключительно важную роль в организации лексикона человека: каждое КТП, подобное полю «Береза», представляет собой некоторую область этого лексикона, который в целом и есть их общая совокупность очень сложной структуры – объемная система систем иерархического характера в виде взиамопересекающихся, накладывающихся, сходящихся, расходящихся и т. д. КТП[20]. Между составляющими эти поля элементами (ими могут быть не только слова, но и словосочетания) существуют собственно тематические отношения, в пределах которых проявляются все виды связей и отношений, возможных между номинативными единицами языка.
Процедура выделения КТП хотя и трудоемка, но довольно проста и легко может быть автоматизирована. С одной стороны, это АЭ с последующей статистической обработкой полученных данных, с другой – она заключается в статистической обработке материалов словарных картотек по употреблениям тематически существенных слов. говорит, например, о 1600 дескрипторах, то есть «основных понятиях, концептах, идеях, охватывающих и организующих всю русскую лексику»[21]. Эти дескрипторы, несомненно, также могут быть систематизированы предлагаемым способом, что и будет, в сущности, их идеографическим описанием. В случае необходимости таким способом могут выявляться как общие КТП всего национального языка, так и поля, характерные для его определенных сфер, стилей и жанров, вплоть до индивидуально-авторских, как в его современном, так и в различных исторических состояниях (по материалам картотек исторических словарей).
Результаты исследования позволяют говорить также о существовании каких-то общих закономерностей построения текстов, об общей стратегии поиска номинативных единиц при их (текстов) порождении. «Маршрут» идея – язык – текст, вероятнее всего, проходит каждый раз не через весь лексикон человека, а лишь через определенную, тематически существенную, часть этого лексикона – через одно (или несколько) из составляющих его КТП. То есть поиск необходимых средств выражения той или иной мысли осуществляется главным образом в области особых блоков лексикона человека, запрограммированных в языковом сознании людей в виде КТП, которые и возбуждаются в первую очередь, как только мы начинаем говорить на определенную тему. При этом, конечно, нельзя не учитывать и все очень сложные взаимосвязи, существующими между этими блоками и их компонентами, что еще подлежит дальнейшему изучению.
Если в онтологическом плане чрезвычайно велика роль словесных ассоциаций в процессах порождения текстов, то в плане онтогенеза можно считать, что все наиболее стереотипные (стандартные, воспроизводимые) вербальные ассоциации возникают и закрепляются в языковом сознании людей в значительной мере (хотя, конечно. и не единственно) под влиянием текстов, как естественный итог постоянного существования людей в мире вещей и мире слов, в условиях той или иной национальной языковой среды обитания (лингвосферы), как результат регулярного совместного появления одних и тех же слов в тематически однородных текстах. Иначе, например, трудно объяснить высокую частотность таких реакций на стимул береза, как стройная, кудрявая, плакучая и т. п. То, что есть в речи, текстах, так или иначе отражается и закрепляется в языковом сознании людей, и наоборот, то, что есть в языковом сознании, так или иначе проявляется (или принципиально всегда может проявиться) в текстах. При этом первичным, вне всякого сомнения, являются материальные тексты, вторичным – идеальное языковое сознание. Весьма существенно также, что чем чаще слова совместно появляются в текстах, тем чаще они появляются совместно и в эксперименте, то есть тем сильнее их ассоциативная связь в языковом сознании носителей языка. Поэтому есть все основания говорить о речевой природе стандартных вербальных ассоциаций.
Таким образом, настоящее исследование показало, что СТП, получаемые путем дистрибутивно-статистического анализа слов-тем, и АП, получаемые путем АЭ, в своих стандартных частях являются, в сущности, идентичными. Можно сказать, что в своей стандартной части АП есть в то же самое время и СТП, а СТП в своей стандартной части есть в то же самое время и АП. Практически это одно и то же. Точнее, это две разные формы реального существования одного и того же (в языковом материале и в языковом сознании) и два разных способа выделения одного и того же (дистрибутивно-статистический анализ и АЭ) – формы существования и способы выделения КТП. Тем самым утверждается языковой статус стандартных вербальных ассоциаций, стандартных частей АП.
Результаты проведенного исследования, с одной стороны, помогают лучше понять некоторые закономерности организации лексикона человека, механизмы речевой деятельности людей, роль стандартных вербальных ассоциаций в этих процессах, их природу и статус, отношение к системе языка и речи и т. п., с другой – они могут быть использованы и в чисто практических целях: при создании программ для информационно-поисковых систем, в решении проблем лексического обеспечения диалога человек – машина на естественном языке, в практике преподавания родных и иностранных языков и т. п.
[1] См. , , К сопоставлению психолингвистического и дистрибутивного анализа семантики // Методы экспериментального анализа речи. Минск, 1968. – С. 122.
[2] См. Клименко психолингвистического изучения лексики. Минск, 1970. – С. 26.
[3] Шайкевич -статистический анализ в семантике // Принципы и методы семантических исследований. М., 1976. – С. 354.
[4] Например, дистрибутивно-статистический анализ существительных со значением «интеллекта» см.: Плотников -статистический анализ лексических значений. Минск, 1979.
[5] Васильев семантических полей // ВЯ. – 1971. № 5. – С. 110.
[6] Там. же. – С. 113.
[7] Морковкин список русских слов (1177 слов) // Лексические минимумы русского языка. М., 1972. – С. 93.
[8] Морковкин список наиболее употребительных русских слов (на материале шести словарей) // Лексические минимумы русского языка. М., 1972. – С. 18.
[9] Шадурский изучение лексики // Методы изучения лексики. Минск, 1975. – С. 49.
[10] Шайкевич -статистический анализ текстов. АДД. – Л., 1982.
[11] Головин слова и контекст // Тезисы докладов межвузовского симпозиума составителей «словаря М. Горького». Киев, 1966. – С. 16-17.
[12] де. Труды по языкознанию. М., 1977. – С. 52.
[13] К проблеме семантической синтагматики // Проблемы структурной лингвистики. М., 1972.
[14] Понятие «имя поля» см.: Новикова значение имени поля и внутренняя структура ядра // Филологические науки. 1985. № 4. – С. 73-75.
[15] «…Закономерности распределения слов в свободном ассоциативном эксперименте и вероятность появления их в потоке речи… чрезвычайно близки». См.: Леонтьев сведения об ассоциациях и ассоциативных нормах // Словарь ассоциативных норм русского языка. М., 1997. – С. 10. Ср. также постановку вопроса о соотношении «ассоциативного поля и семантической микросистемы языка - семантического поля» в работе: Новикова эксперимент как метод изучения семантических отношений в лексике // Вопросы семантики. Калининград, 1983. – С. 8-13.
[16] На уроке – анализ текста. Л., 1982. – С. 39-44.
[17] В сборе материала принимали участие и .
[18] Ср. понятие субъективной и объективной оценки частот: Фрумкина элементов текста и речевое поведение. М., 1971. – С. 7-10.
[19] О двух путях реконструкции лексикона, находящихся в «отношении взаимодополнительности друг к другу» см.: Караулов язык и языковая личность. М., 1987. – С. 107.
[20] См.: Залевская исследование принципов организации лексикона человека (на материале межъязыкового сопоставления результатов ассоциативного эксперимента). АДД. Л., 1980.
[21] Анализ метаязыка словаря с помощью ЭВМ. М., 1982. – С. 40.
